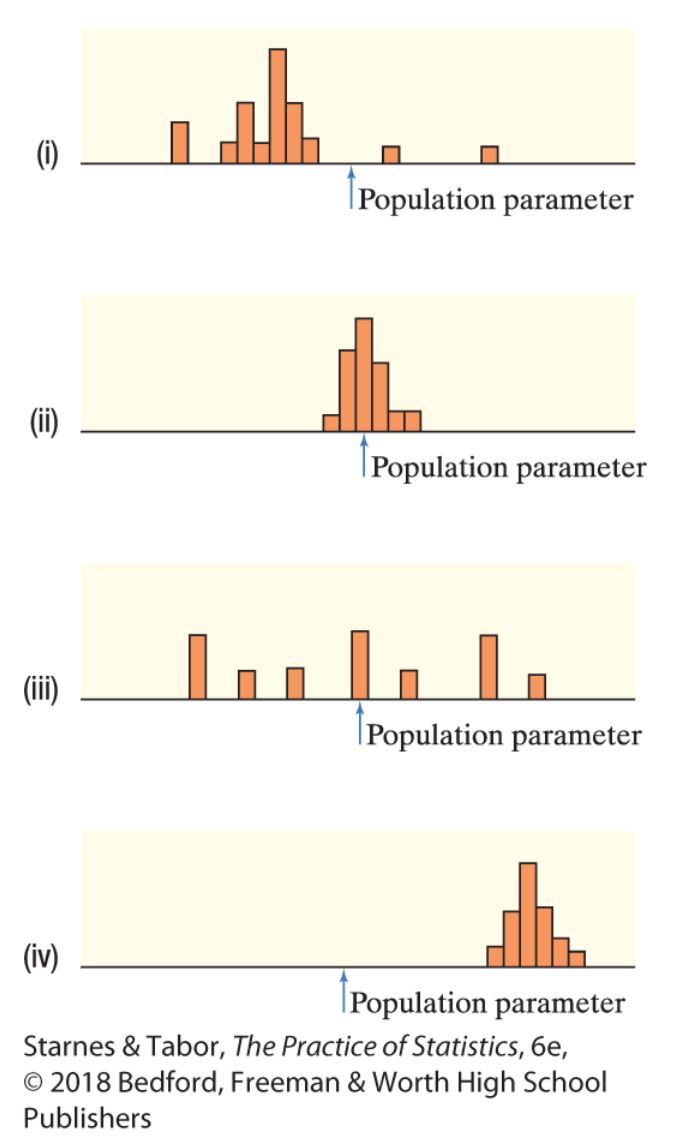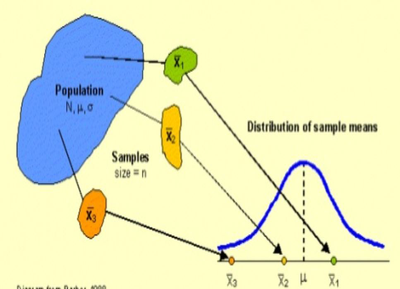
First, we'll create the same sampling distribution that we created yesterday. Use the model above to create the sampling distribution for the mean scores of samples of 2 students (n=2) taken from a population of 48 students (N=48).
1) Set the slider and click "setup" and "collect samples." The sampling will happen faster if you pull the "model speed" slider all the way to the right.
2) Click the button that says "tables" in the upper left, then "data set" in order to see your data table. You can drag it around in the CODAP window to wherever you want it.
3) Now we'll set up the graph. First, click the "graph" button in the top left. Then click the "click here" along the x-axis and select "mean."
4) We're also going to find the mean of the data in this graph (That is, the mean of all the means from each sample). To do that click on the ruler to the right of the graph and check "mean." There should now be a line in the middle of your sampling distribution for the mean, and you can hover over it to find out its value.
The mean score for our population of 48 students is 3.4. Is your mean close to that value?